The efficiency of a regular expression depends on a lot of factors. Each regular expression engine has different optimizations. The text you’re applying the regular expression to also has a great impact. The more positions in the text where the regular expression can be partially matched, the more time the regex engine spends on those failed attempts. All this means that there’s no straightforward way to benchmark regular expressions using the traditional (virtual) stopwatch outside of your actual application.
Still, RegexBuddy’s debugger can give you a good view of the overall complexity of a regular expression. Essentially, the more steps the debugger needs to either find the match or declare failure, the more complex the regular expression. Particularly steps marked as “backtrack” are expensive.
When comparing the efficiency of regular expressions, you should run the debugger both on highlighted matches, as well as at positions where the regular expression cannot be matched. When comparing regular expressions to match a particular HTML tag, for example, place the text cursor on the Test panel before the < of an HTML tag that should not be matched. Click the Debug button to see how many steps it takes to figure out that tag shouldn’t match.
Sometimes, the performance difference between two regular expressions can be quite severe. In the regular expressions tutorial, there’s an example illustrating what is called catastrophic backtracking. The faulty regular expression needs 60,315 steps to fail a short string, a number that grows exponentially with the string’s length. The improved regular expression needs only 36 linear steps to match, and another constant 12 to fail.
When comparing two regular expressions, first observe how the number of steps RegexBuddy needs grows. If one regex uses a constant number of steps while the other needs more steps for longer strings, the constant regex is by far the best, even if it needs more steps. However, don’t grind your teeth trying to make it constant. It’s often impossible for complex text patterns.
If neither regex is constant, compare their growth rate relative to the length of the string. You’ll need to test at least three string lengths. First, check if the growth is linear. It is when. the number of steps roughly doubles when you double the length of the string. If one regex grows linearly and the other grows exponentially, the linear regex is always better, even if it needs more steps. As the length of the string grows, the exponential regex will soon exhaust the capabilities of any regular expression engine.
Comparing the actual number of steps only makes sense if both regular expressions are either constant or linear. The one with fewer steps wins. If both are exponential, start with trying to make one of them linear. It’s not always possible, but certainly worth trying.
You should always benchmark your regular expression both on test subjects that match, and test subjects that don’t. In fact, the performance killer is usually slow failure rather than slow matching. Often, a regular expression is used to extract small bits from a larger file. In that cause, the regular expression’s performance at positions in the file where it cannot match is far more important than its performance at matching. If you want to extract 10 strings of 100 characters from a file that’s a million characters long, the regular expression has to match 10 times, and fail 999,000 times.
Writing a regular expression that matches linearly is much easier than writing one that fails linearly. When a regex fails, the regular expression engine does not give up until it has tried all possible permutations of the all the alternations and quantifiers in your regular expression. You’ll be surprised how numerous those are.
There are two important techniques to make an exponential regex linear. The easiest and most important one is to make adjacent regex tokens mutually exclusive whenever possible. When writing a regex that locates delimited content, and the delimiters cannot appear (in escaped form) in the content, specify that in your regular expression. Doing so makes sure that the regex engine does not attempt to include the delimiter as part of the content, which significantly reduces the number of pointless permutations the regex engine tries.
As a test, compare the regular expressions "[^"]*" and ".*?" on the test subject "test". Both regexes match, but the former needs 3 steps in the debugger, while the latter needs 11. Now test "this is a test". The former still needs 3 steps, but the latter needs 31. Clearly, a greedy negated character class is more efficient than a lazy dot. In actual search time, the impact of this isn’t measurable when your input files only contain short strings. It can be significant when you’re searching thousands of files with strings thousands of characters long.
The second technique is the use of atomic grouping and/or possessive quantifiers. Both these features are a fairly recent addition to the regular expression culture. RegexBuddy supports both, but your programming language might not. These regex tokens come in handy when you can’t use negated character classes. Basically, an atomic group locks in the part of the text the regex matched so far. It says: when you’ve reached this point, don’t bother going back to try more permutations. If you can’t find a match, fail right away.
In many situations, you cannot replace a lazy dot with a negated character class to prevent the delimiter from being included in the content. Then you can use an atomic group to achieve the same result. Simply place the atomic group around the lazy dot (or whatever repeated regex token that shouldn’t match the following delimiter) and the delimiter that follows it. Then, as soon as the delimiter is matched, the atomic group is locked down. If the remainder of the regex fails, the lazy dot won’t get the chance to expand itself and gobble up the delimiter.
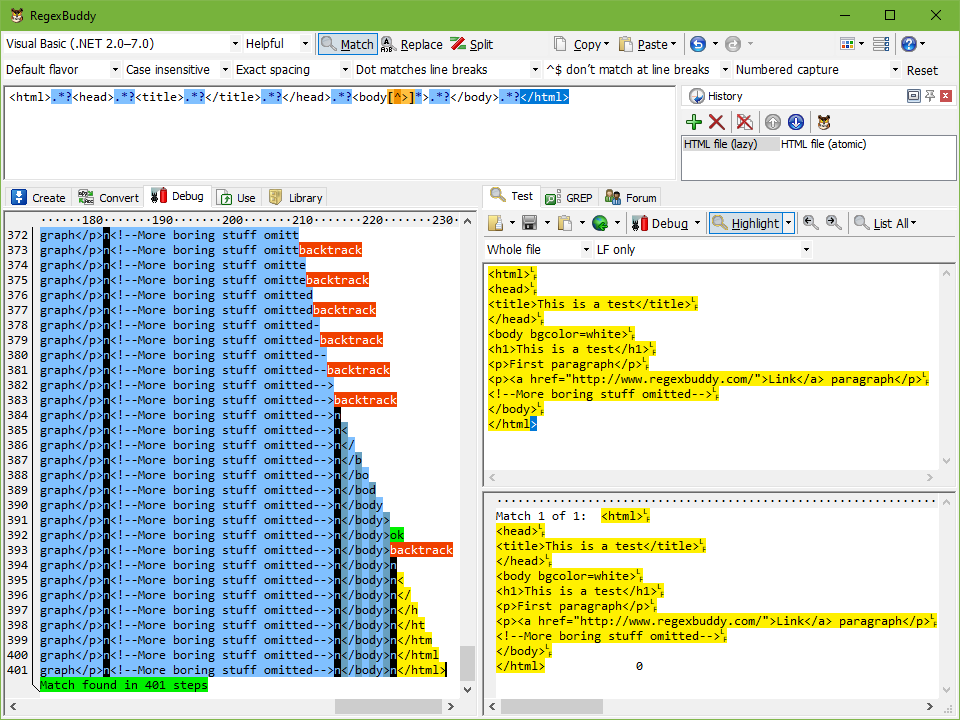
The tutorial topic on catastrophic backtracking includes a detailed example. You can easily see the effect for yourself in RegexBuddy. The two regular expressions are included in RegexBuddy’s library as “HTML file” and “HTML file (atomic)” along with identical test data. Click the Use button on the Library panel and pick “Use regex and test data”.
Both regexes highlight the whole test subject. (If not, you cheated and used copy and paste rather than the “Use regex and test data” command, which doesn’t turn on the “dot matches line breaks” option these regexes need.) If you click on the highlighted match and then click the Debug button, RegexBuddy finds the match in 401 steps for the first regex, and 407 steps for the atomic regex.
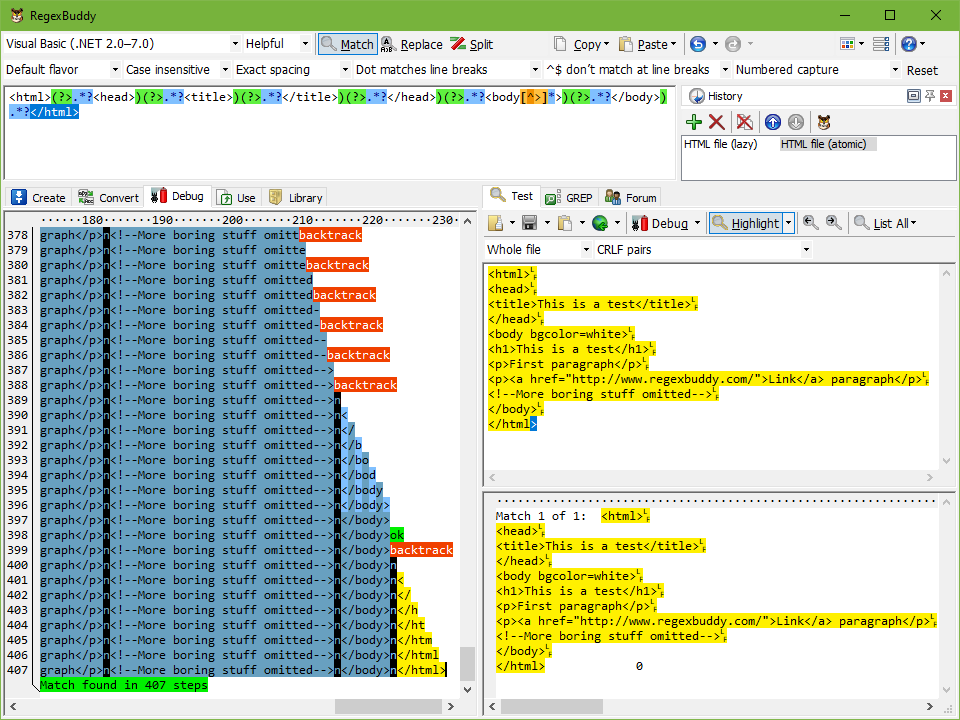
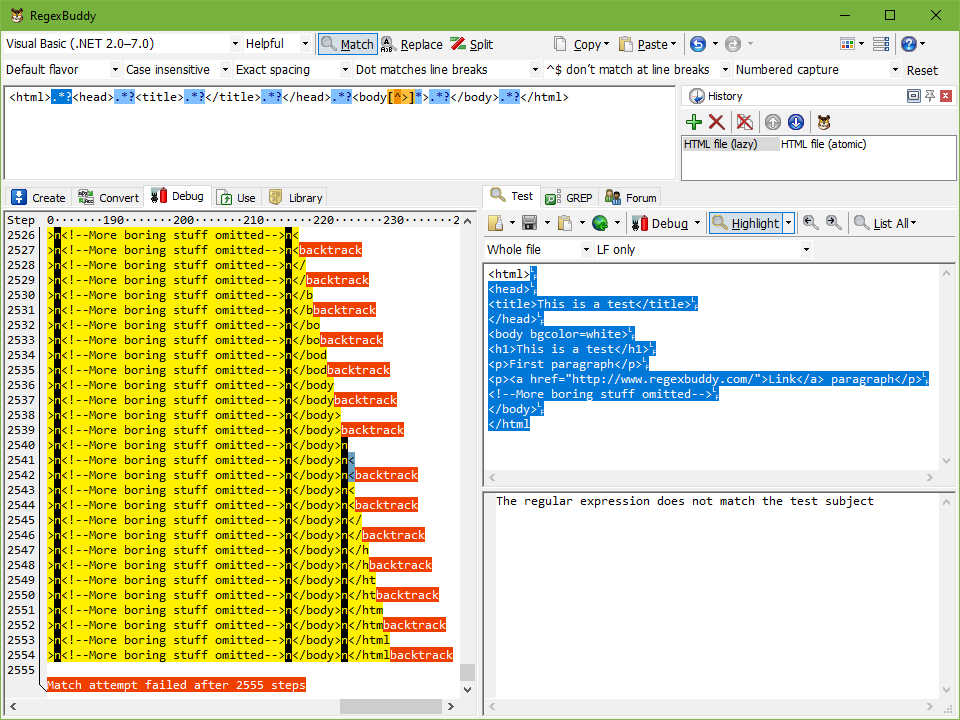
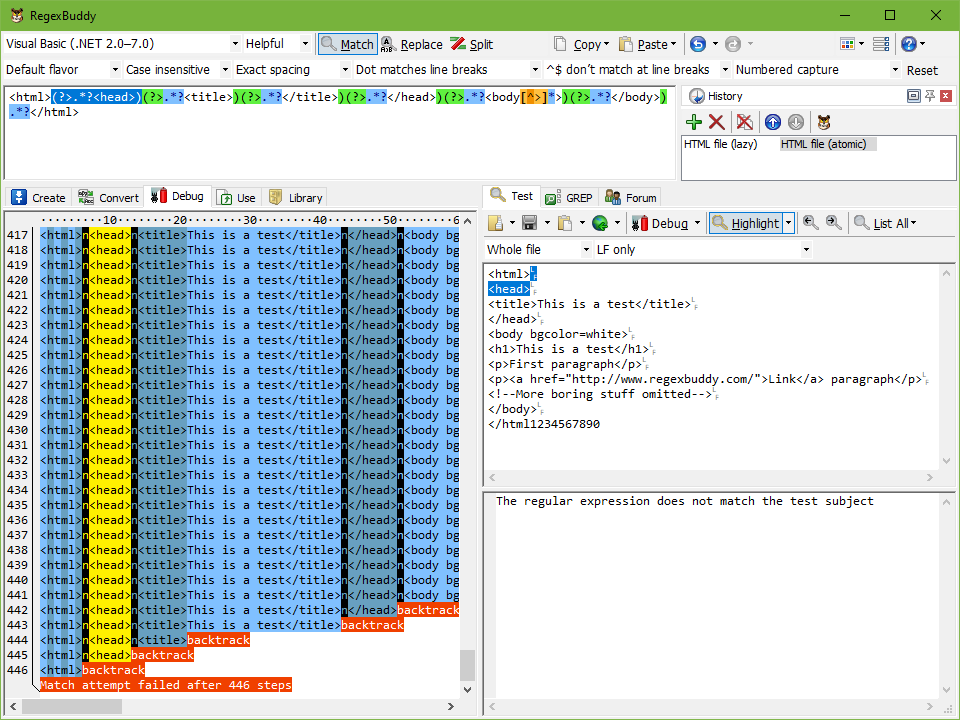
Now, delete the very last > character from the test subject. The match highlighting disappears immediately, as the regex no longer matches the test subject. Move the text cursor immediately to the left of the very first < character in the file. Then click the Debug button. The first regex needs 2,555 steps to conclude failure. The regex using atomic grouping needs only 426 steps.
If you look closely at the debugger output, you’ll see that the first regex produces some kind of vertical sawtooth, extending all the way, backing up a little, extending all the way, backing up some more, etc. The second regex, however, gradually matches the whole file, and then drops everything in just a few steps.
In the screen shots below, you can clearly see that in the one but last step of the first regex, the first .*? in the regex has “eaten up” the whole file. The second regex only has one “backtrack” for each .*?.
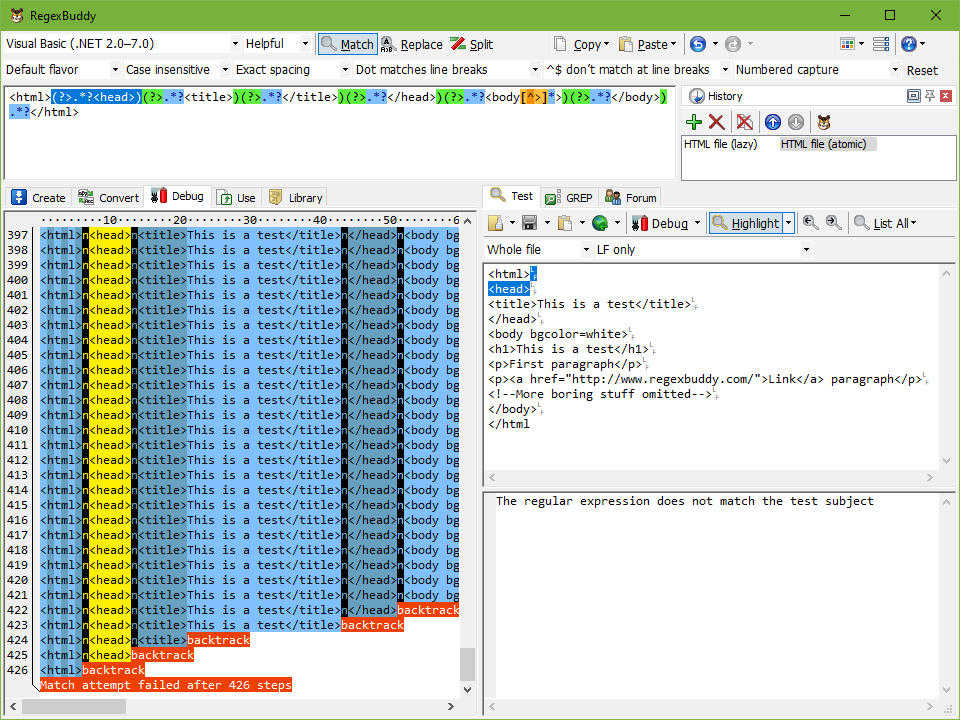
As a final test, type 1234567890 at the end of the test subject, so it ends with </html1234567890. Put the text cursor back before the very first < character in the file, and click Debug. The regex without atomic grouping now needs 2,695 steps, while the atomic regex needs only 446. The 10 additional characters add 140 steps for the first regex, but only 20 for the second. That’s 14-fold the number of characters we added for the first regex, but only 2-fold for the second.
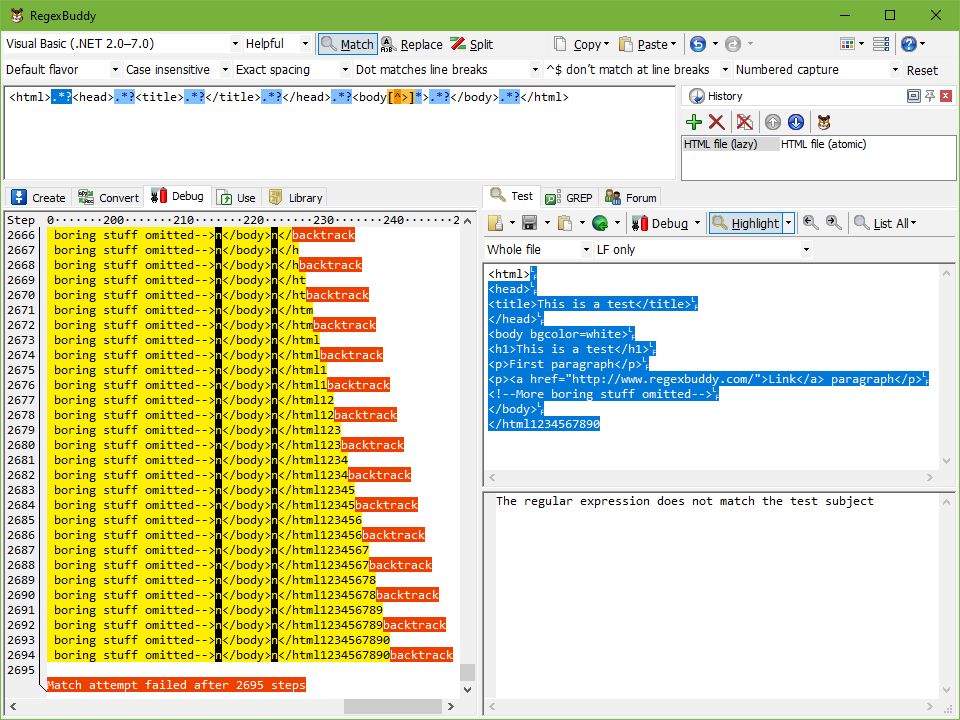
By using atomic grouping, we achieved a 7-fold reduction in the regular expression’s complexity. Both regular expressions are in fact linear. But two steps per character is a huge savings from fourteen steps per character. If you’re scanning through a megabyte worth of invalid HTML files, the optimized regex has 2 MB of work to do, while the original regex has 14 MB of work to do.
If you wonder where these numbers come from, the regex has seven lazy dots. The lazy dot matches a character (one step), proceed with the next token, and then backtrack when the next token fails (second step). When using atomic grouping, each lazy dot matches each character in the file only once. None of the dots can match beyond their delimiting HTML tag. This yields two steps per character. In the original regex, the dots can backtrack to include their delimiters and match everything up to the end of the file. Since there are seven lazy dots, all characters at the end of the file are matched by all seven, taking fourteen matching steps.
Had you only compared the performance of these regexes on a valid HTML file, you might have been fooled into thinking the original is a fraction faster. In reality, their performance at matching is the same, since neither regex does any more backtracking than needed. It’s only upon failure that backtracking gets out of hand with the first regex.