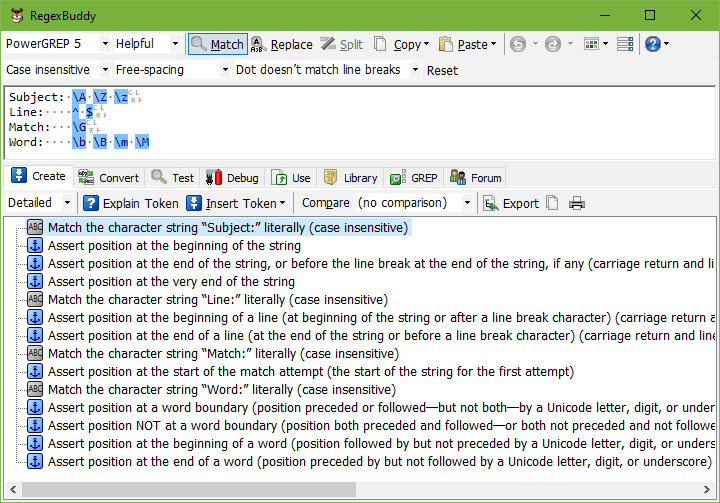
Insert a Regex Token to Match at a Certain Position
The Insert Token button on the Create panel makes it easy to insert the following regular expression tokens to match at a certain position. They’re called “anchors” because they essentially anchor the regular expression at the position they match. See the Insert Token help topic for more details on how to build up a regular expression via this menu.
RegexBuddy supports the following anchors. Most applications only support some of these, and there is quite a bit of variation in the syntax.
- Beginning of the string: \A or \‘ matches at the very start of the string only. If these are unsupported, ^ is inserted if “^$ match at line breaks” can be turned off.
- End of the string: \z or \' matches at the very end of the string only. If these are unsupported then ^ is inserted if “^$ match at line breaks” can be turned off and the application does not allow it to match before the final line break in that mode.
- End of the string or before the final line break: \Z matches at the very end of the string, or before the line break, if any, at the very end of the string. If the application does not support \Z or matches at the end of the string only, then ^ is inserted if “^$ match at line breaks” can be turned off and the application allows it to match before the final line break in that mode.
You can use \Awhatever\z to verify that a string consists of nothing but “whatever”.
- Beginning of a line: Inserts ^ and turns on “^$ match at line breaks” to make ^ match at the start of a line.
- End of a line: Inserts $ and turns on “^$ match at line breaks” to make $ match at the end of a line.
You can use ^whatever$ to match “whatever” only if it can be found all by itself on a line. Use ^.*whatever.*$ to completely match any line that has “whatever” somewhere on it.
- Start of the match attempt: \G matches at the start of the current match attempt. In some applications, \A and \‘ are implemented incorrectly, causing them to match at the start of any match attempt rather than just the beginning of the string. For such applications, “start of match attempt” inserts \A or \‘ and “beginning of the string” is grayed out.
- End of the previous match: \G matches at the end of the previous match, or at the very start of the string during the first match attempt. There is only a difference between the end of the previous match and the start of the match attempt if the previous match was a zero-length match. Then the start of the match attempt is one character beyond the end of the preceding zero-length match.
Put \G at the start of your regular expression if you only want to attempt it at one position, without going through the whole subject string.
- Word boundary: \b or \y matches between a word character and a non-word character, as well as between a word character and the start and the end of the string.
- Non a word boundary: \B or \Y matches between two word characters, as well as between two non-word characters. Essentially, it matches everywhere \b doesn’t.
- Beginning of a word: \m, \<, or [[:<:]] matches at any position followed by but not preceded by a word character.
- End of a word: \M, \>, or [[:>:]] matches at any position preceded by but not followed by a word character.
Placing word boundaries before and after a word as in \bword\b or \<word\> is the regex equivalent of a “whole words only” search.