Insert a Regex Token to Change a Matching Mode
The Insert Token button on the Create panel makes it easy to insert the following regular expression tokens to change how the regular expression engine applies your regular expression. These tokens are called mode modifiers.
Mode modifiers are useful in situations where you can’t set overall matching modes like you can with the combo boxes on RegexBuddy’s toolbar. Mode modifiers are not supported by all applications that support matching modes. But in applications that do, mode modifiers always override modes set outside of the regex (combo boxes in RegexBuddy).
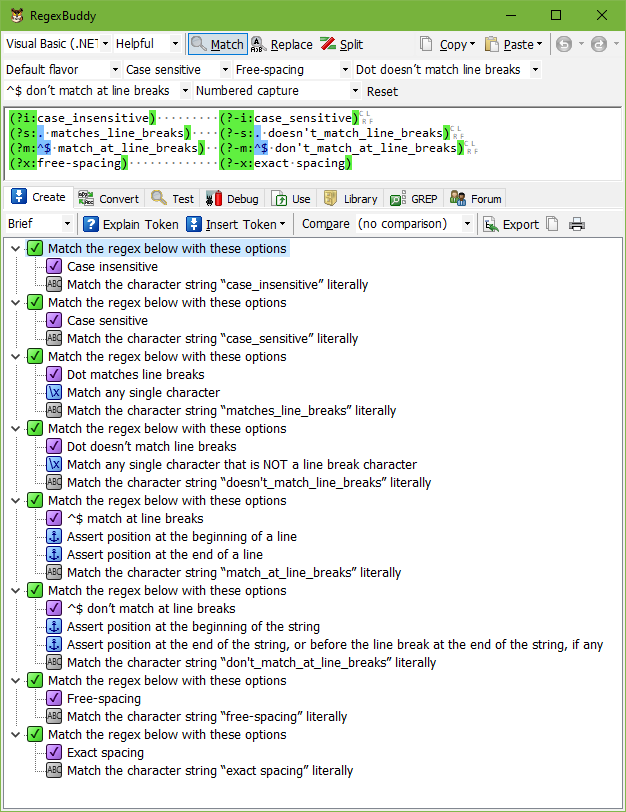
- Turn on case insensitive: Differences between uppercase and lowercase characters are ignored. cat matches CAT, Cat, or cAt or any other capitalization in addition to cat.
- Turn on free-spacing: Unescaped spaces and line breaks in the regex are ignored so you can use them to format your regex to make it more readable. In most applications this mode also makes # the start of a comment that runs until the end of the line.
- Turn on dot matches line breaks: The dot matches absolutely any character, whether it is a line break character or not. Sometimes this option is called “single line mode”.
- Turn on ^$ match at line breaks: The ^ and $ anchors match after and before line breaks, or at the start and the end of each line in the subject string. Which characters are line break characters depends on the application and the line break mode. Sometimes this option is called “multi-line mode”.
Some regular expression flavors also have mode modifiers to turn off modes, even though all modes are off by default. These flavors allow you to place mode modifiers in the middle of a regex. The modifier will then apply to the remainder of the regex to the right of the modifier, turning its mode on or off. With these flavors, if you select part of your regex before choosing a mode modifier item in the Insert Token menu, RegexBuddy will create a mode modifier span that sets the mode for the selected part of the regex only.
- Turn off case insensitive: Differences between uppercase and lowercase characters are significant. cat matches only cat. Same as selecting “case sensitive” in the combo boxes.
- Turn off free-spacing: Unescaped spaces, line breaks, and # characters in the regex are treated as literal characters that the regex must match. Same as selecting “exact spacing” in the combo boxes.
- Turn off dot matches line breaks: The dot matches any character that is not a line break character. Which characters are line break characters depends on the application and the line break mode. Same as selecting “dot doesn’t match line breaks” in the combo boxes.
- Turn off ^$ match at line breaks: The ^ and $ anchors only match at the start and the end of the whole subject string. Depending on the application, $ may still match before a line break at the very end of the string. Same as selecting “^$ don’t match at line breaks” in the combo boxes.