The Insert Token button on the Create panel makes it easy to insert the following replacement text tokens that reinsert (part of) the regular expression match. See the Insert Token help topic for more details on how to build up a replacement text via this menu.
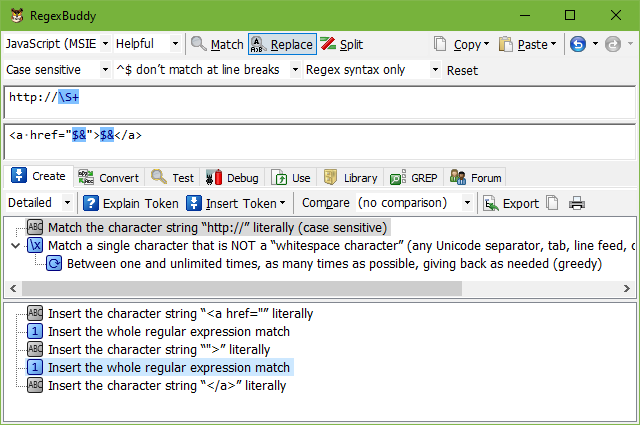
Inserts a token such as $& or $0 into the replacement text that will be substituted with the overall regex match. When using a regex that matches a URL, for example, the replacement text <a href="$&">$&</a> will turn the URL into an anchor tag.
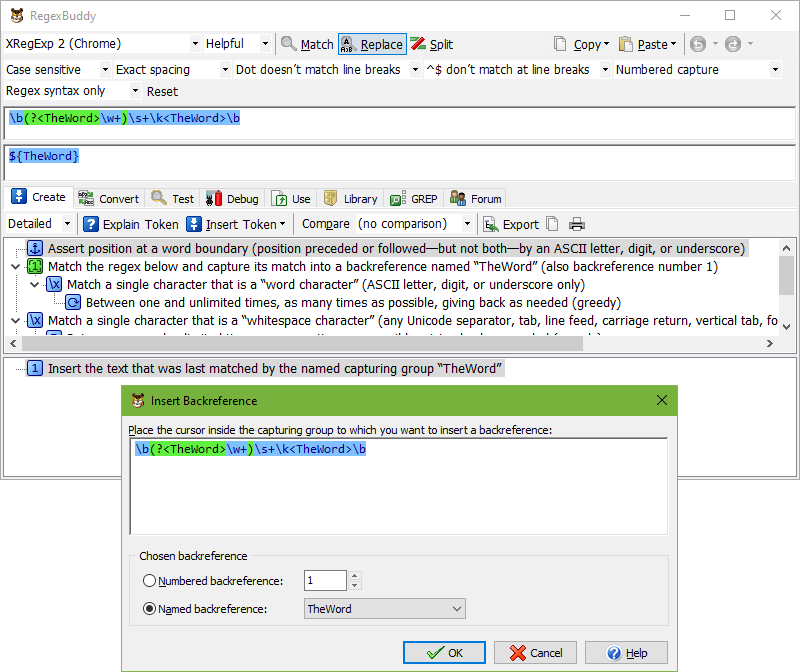
If you’ve added one or more numbered or named capturing groups to your regular expression then you can insert backreferences to those groups via Insert Token|Backreference. In the window that appears, click inside the capturing group to which you want to insert a backreference. RegexBuddy automatically inserts a named backreference when you select a named group, and a numbered backreference when you select a numbered group, using the correct syntax for the selected application.
The backreference will be substituted with the text matched by the capturing group when the replacement is made. If the capturing group matched multiple times, perhaps because it has a quantifier, then only the text last matched by that group is inserted into the replacement text.
For example, the regular expression \b(\w+)\s+\1\b matches a doubled word and captures that word into numbered group #1. A search-and-replace using this regex and $1 or \1 as the replacement text will replace all doubled words with a single instance of the same word.
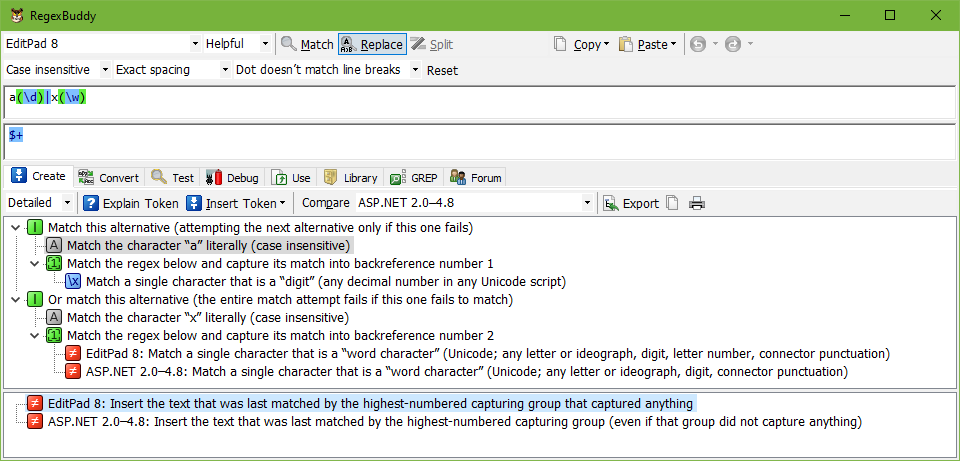
Some flavors support the $+ or \+ token to insert the text matched by highest-numbered capturing group into the replacement text. Unfortunately, it doesn’t have the same meaning in all applications that support it. In some applications, it represents the text matched by the highest-numbered capturing group that actually participated in the match. In other applications, it represents the highest-numbered capturing group, whether it participated in the match or not.
For example, in the regex a(\d)|x(\w) the highest-numbered capturing group is the second one. When this regex matches a4, the first capturing group matches 4, while the second group doesn’t participate in the match attempt at all. In some applications, such as EditPad or Ruby, $+ or \+ will hold the 4 matched by the first capturing group, which is the highest-numbered group that actually participated in the match. In other applications, such as .NET, $+ will be substituted with nothing, since the highest-numbered group in the regex didn’t capture anything. When the same regex matches xy, EditPad, Ruby, and .NET all store y in $+.
Also note that .NET numbers named capturing groups after all non-named groups. This means that in .NET, $+ will always be substituted with the text matched by the last named group in the regex, whether it is followed by non-named groups or not, and whether it actually participated in the match or not. This is yet another reason why we recommend not mixing named and numbered capturing groups in a single regex.