The Insert Token button on the Create panel makes it easy to insert a tokens to match one character out of many possible characters. See the Insert Token help topic for more details on how to build up a regular expression via this menu.
A character class matches a single character out of a set of characters. Inside the character class, you can use a wide range of regular expression tokens. Many of these also work outside character classes. Some of them are unique to character classes.
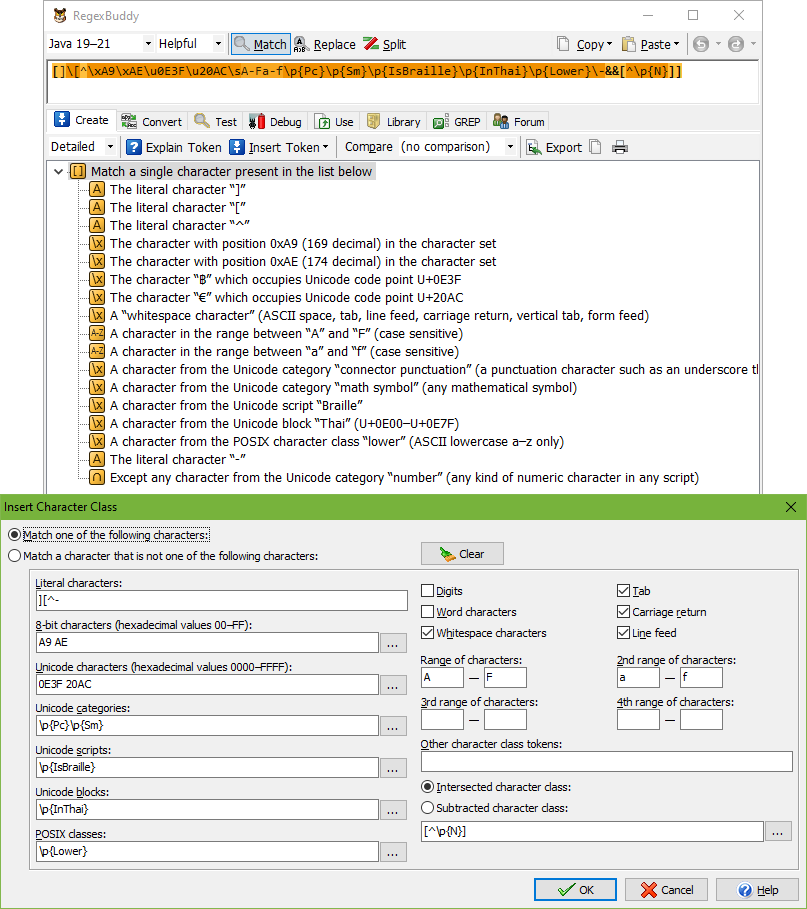
First, you can specify if you want to match a character from the list of characters that you specify, or if you want to match a character that’s not in your list. If you’ve already used the Insert Character Class dialog during the current RegexBuddy session, it will default to the last class you edited. Click the Clear button if you want to start with a clean slate.
To match a character out of a bunch that you can type on your keyboard, simply type them into the Literal characters box. RegexBuddy takes care of escaping those characters that have a special meaning inside character classes. Incidentally, these are not the same characters as those that have a special meaning in regular expressions outside character classes.
If you want to match a character out of a series that you cannot type on your keyboard, click the ellipsis (...) buttons next to the 8-it characters or Unicode characters fields to pick the characters you want to insert. You’ll get the same selection dialogs as when you try to insert a token for matching 8-bit or Unicode characters directly into your regular expression. RegexBuddy will generate the same \xFF and \uFFFF syntax, though the \x and \u will not be shown in the Insert Character Class dialog for brevity.
The ellipsis buttons next to the Unicode categories, Unicode scripts, Unicode blocks, and POSIX classes fields also show the same dialogs as their corresponding items in the Insert Token menu. The same regex tokens will be inserted into the character class, and shown in the Insert Character Class dialog.
The second column in the dialog box starts with six checkboxes. The three at the left allow you to include three common shorthand character classes in your character class. Their negated counterparts don’t have checkboxes. Using negated shorthands in character classes is not recommended. The three other checkboxes allow you to easily insert three commonly used non-printable characters. If you want to use others, you can enter them in the “other character class tokens” field further down.
The Insert Character Class dialog provides four sets of edit boxes where you can specify character ranges. Enter the first character in the range at the left, and the last character at the right of the long dash. Though you can use any sort of character as the start or end point of a range, you should use only letters and digits to define ranges. It’s easy for anyone to understand which characters are included in a range of letters or digits. If you want to include a range of 8-bit or Unicode characters, you can use the \xFF or \uFFFF syntax to specify the range’s endpoints.
In the “other character class tokens” field you can enter additional tokens that RegexBuddy should include into the character class. Whatever you type in here should be valid regular expression syntax inside a character class. For example, you could type \e to include the escape character. Essentially, this is a catch-all field if you like to use certain rarely used regex constructs that RegexBuddy doesn’t provide special support for in its Insert Character Class dialog. Typically, you’ll only use this if you double-clicked on a character class in the regex tree of a regular expression created by somebody else.
The “intersected character class” and “subtracted character class” field allows you to specify a character class that should be intersected with or subtracted from the one you’ve just specified. Click the ellipsis (...) button to open a second Insert Character Class dialog to define the character class to be intersected or subtracted.
Intersection is written as [A&&[B]] and results in a character class that only matches characters that are in both sets A and B. Subtraction is written as [A-[B]] and results in a character class that only matches characters that are in set A but not in set B. Both options will be available if the current application supports character class intersection or character class subtraction. [A-[^B]] is the same as [A&&[B]], and [A&&[^B]] is the same as [A-[B]], so RegexBuddy can easily adapt your choice to the available syntax. In these examples, A and B are placeholders for larger sets of characters. For example, if you specify the Unicode script \p{Thai} for your base character class, and you specify the Unicode category \p{Number} for your subtracted character class, then the resulting class [\p{Thai}-[\p{Number}]] or [\p{Thai}&&[^\p{Number}]] will match any Thai character that is not a number.